


Nvidia - Part 3: Beyond GPUs, Software Moat, and Competition
Deep dive on Nvidia

Despite being a hardware company, software has been engrained in Nvidia’s DNA from its very early days. In the 1990s it broke away from standard industry practices and started using software emulation to develop GPUs at a faster cycle than anyone in the industry. In 2001 it developed the very first programmable pixel shader with its GeForce 3 graphics card, a revolutionary idea as it was software which for the first time allowed graphics to be programmed on the fly. It then went on to pioneer new visual techniques such as ray tracing and deep learning super sampling1, which require significant software simulation working in tandem with powerful hardware. Most importantly however, Nvidia’s massive strategic and financial investment in CUDA and all the software libraries that sit on top have established a significant moat for the company in the data center, its now most important business.
The reason for Nvidia’s integrated approach in the data center is that it realised that it’s not in the business of selling hardware, but instead selling solutions to problems. Customers are often trying to get to an outcome, such as implementing AI/ML within their business, without necessarily being experts in hardware, coding, and data analytics. By providing customers with ready-made solutions which integrate hardware and software, it not only increases the switching costs as Nvidia become more deeply engrained in customers’ operations, but it also bestowed Nvidia with significant pricing power which transformed its margin profile to be even higher than those of Apple, the company that’s held up as the pinnacle of premium hardware differentiated with software.

Following on from Part 2, this article will explore the moat that Nvidia has established through its full-stack computing approach, and also examine the competitive landscape which is threatening to encroach on its position.
A THREE-CHIP COMPANY
The scale of computing requirements is exploding as the size of AI models grows exponentially. Data is increasingly being processed not just one chip or server, but across multiple chips and servers at data center scale. To ensure performance is as finely tuned as possible, and also to perhaps prepare themselves for a future that may require more flexible technology use, all of the chip companies are expanding beyond their legacy core chip. For Nvidia that means expanding beyond the GPU into DPUs (data processing units) and CPUs. To quote Jensen from an interview a few years ago- “The onion, celery, and carrots – the holy trinity of computing soup – is the CPU, the GPU, and the DPU. These three processors are fundamental to computing”.
Networking and DPUs
Connectivity and bandwidth are increasingly becoming a bottleneck in the data center as the size of workloads and datasets increases. Having long recognised this, Nvidia has been pushing into networking with their own tailored solutions such as NV-Link (a bridge that connect GPUs together at fast speeds without having to go through a PCIe bus) and more recently NV-Switch (a mechanism to connect multiple GPUs together). Think of these as super highways between the GPUs allowing high-speed connectivity. Essentially it serves a similar data transmission purpose as the PCIe on a motherboard, but it does it 10x faster. Nvidia’s DGX servers (described in Part 2) bring together its GPUs and these high-speed interconnects in one system.
Interconnects are one part of the networking story. The other is the switches and controllers that connect computers to the network. Every server in a data center is connected to the Ethernet network through network interface cards, or NICs, which are simple devices that allow packets of data into and out of a server. As network speeds and data volume increased over time, more and more of the CPU’s resources were getting tied up in processing this network traffic. So the NICs eventually evolved to be programmable and offload some of these tasks from the CPU, becoming what’s known as “smartNICS”. However with the increasing use of software defined storage and networking for high performance applications such as AI, the burden on the CPU kept increasing - as much as 30% of a CPU’s resources on every server are being consumed by low-level infrastructure tasks such as data transport and processing, storage, and security. Enter Mellanox and the data processing unit (DPU).
In 2020 Nvidia completed its largest acquisition to date - a $7bn acquisition of Mellanox, an Israel-based company that specializes in high-performance networking solutions. Incorporating Mellanox’s technology, Nvidia developed its Bluefield range of DPUs. Described by Nvidia as a “programmable data center on a chip”, Bluefield DPUs are Arm-based chips which sit alongside the CPU on a server, offloading and accelerating all of these infrastructure tasks, in turn freeing up all of the CPU resources to run applications and significantly improving customers’ cost of operations.
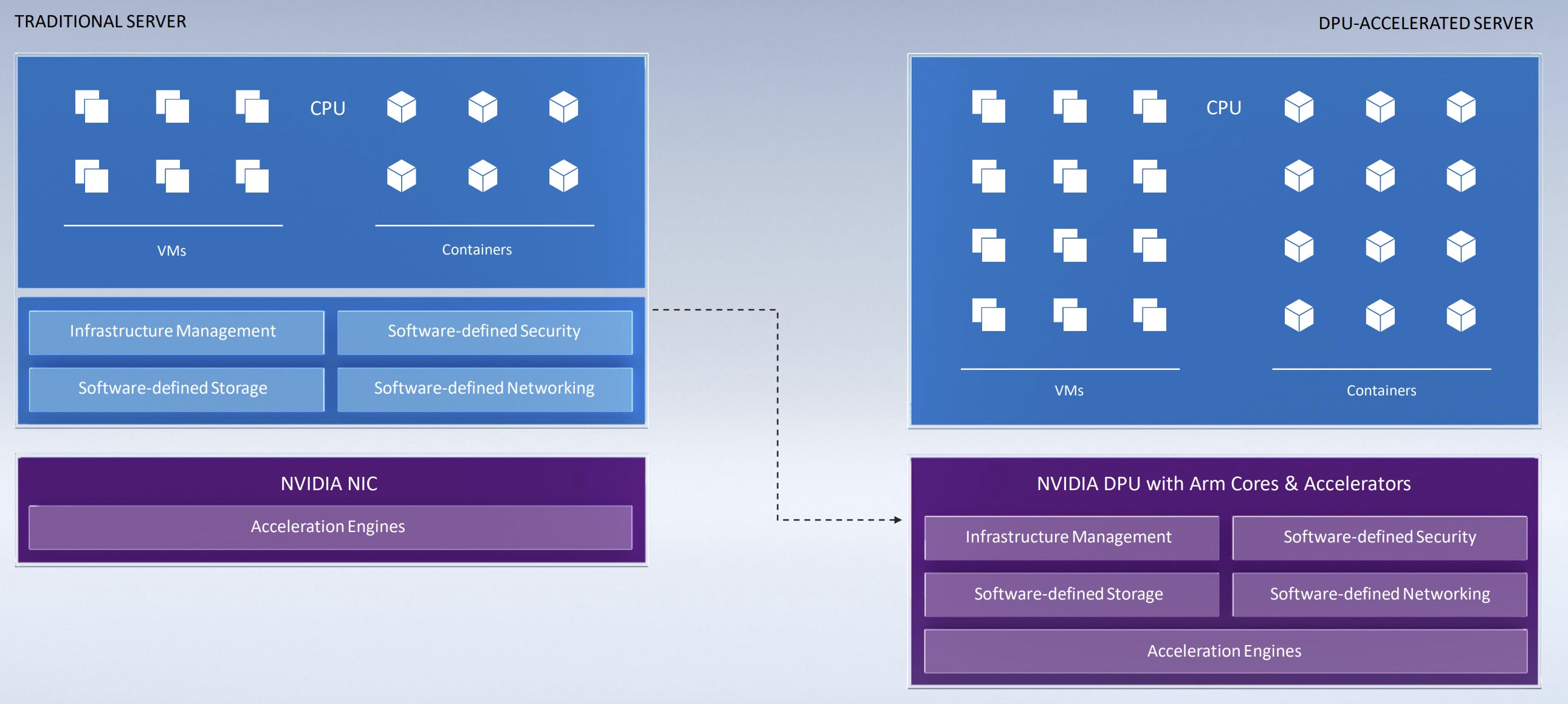
According to Nvidia, it would take 125 x86 CPU cores to perform all of the activities of a Bluefield 2 DPU, and the Bluefield 3 and 4 are multiple times more powerful than that. To be clear though, DPUs are essentially just advanced versions of smartNICs which have been used by cloud vendors for almost a decade in some cases, and which Mellanox itself used to sell pre-Nvidia acquisition. Bluefield DPUs are therefore more evolutionary rather than revolutionary, but nonetheless they form an important part of Nvidia’s data center platform. More broadly, as the below chart shows Mellanox and its range of networking solutions has been a nice contributor to Nvidia’s data center revenues particularly in recent quarters, and given management’s focus on this area I’d expect this trend to continue.

CPUs
More recently, Nvidia announced its entry into the CPU market with the launch of its Grace CPU. Designed using energy-efficient Arm cores, Grace is a specialised CPU created to process the heaviest duty, largest, lowest-latency requiring AI and HPC workloads. Its performance will supposedly be competitive with the best of AMD’s and Intel’s x86 CPUs, and it will be capable of running all of the software that Nvidia has created to run on GPUs. The Grace CPU is intended to be a full peer to the next gen Hopper GPU, perfectly integrated and optimised to work in tandem to run the largest workloads and AI models of the future. It can combine with the Hopper in various configurations, such as the Grace-Hopper superchip with a direct chip-to-chip connection with NVLink (transmitting data at 900GB/s). This will allow it to transport data to Nvidia GPUs faster than any other CPU.
According to Nvidia, Grace is not directly competing with AMD and Intel given its focus on the highest end of AI and HPC workloads - essentially at this stage a small sliver of the CPU market. Of course Nvidia would be very careful not to tread on AMD’s and Intel’s toes too much (at least publicly) given it still partners with them in many respects. Already however we are seeing Nvidia incorporate Grace into its latest all-in-one systems where it previously may have used AMD CPUs (like in its DGX system), so it’s hard to conclude that the Grace is not going to compete with AMD and Intel to some extent. Essentially it means that all three of these companies are converging across all of the key data center computing chips (more on this in Competition below).
Grace and Grace-Hopper superchips has been adopted into designs by all the leading computer OEMs and two supercomputing research labs. Nonetheless we probably need to temper our expectations for Grace adoption, as it needs to be put in the context of overall Arm adoption vs. x86 which dominates data center computing. Arm has struggled to get adoption in the data center as most software is generally designed to run on Intel and AMD’s x86 architecture. According to one expert:
“the key question is whether the Grace CPU is cheaper or faster enough to offset the risk of adding heterogeneity and having to deal with incompatibilities of software stacks? I suspect there, you’ll see very slow uptake. There have been a lot of attempts for Arm to penetrate in the HPC market before and it’s never really got anywhere”.
Third Bridge expert call - former Nvidia executive
Of course this may change over time as companies like Nvidia and AWS invest in the Arm ecosystem (AWS’s Graviton CPU is Arm-based and is capturing decent share of AWS compute cycles). Ampere’s successes in getting wins in major hyperscalers is also promising for the Arm ecosystem. Ark Invest believes that over the next 10 years Arm and RISK-V CPUs will surpass Intel and AMD’s market share as they become cheaper and faster. If that’s the case, perhaps Nvidia is positioning itself on the right side of disruptive trends in the CPU market. Time will tell.
So in summary, the GPUs accelerate AI and HPC workloads, CPUs run the operating system and other applications, and DPUs take on network data processing, security and storage. These chips form the foundations of Nvidia’s data center hardware roadmap, and the plan is to release them on two year cycles.

THE SOFTWARE STACK - NVIDIA’S MOAT IN THE DATA CENTER
Hardware is important but only useful if the enabling software allows developers to unlock the hardware’s full potential. That takes the form of an end-to-end software stack that enables developers to optimize and deploy a broad range of AI model types.
In the early 2000s, GPUs had limited use outside of gaming because unlike CPUs, they were difficult for developers to program on and manipulate. Jensen however was already getting a sense that there was a much larger market potentially available to be unlocked. So to enable programmability of GPUs, Nvidia made a massive strategic and financial investment in developing what it called Compute Unified Device Architecture (CUDA), a proprietary software programming layer for use exclusively with Nvidia's GPUs. CUDA provides the libraries, the debuggers and APIs which make it a lot easier to make GPUs programmable for general purpose computing tasks. CUDA is backwards compatible with the hundreds of millions of Nvidia GPUs that were out there, and it achieved wide adoption as Nvidia consistently invested in the ecosystem.
The moat that CUDA developed around Nvidia in the data center cannot be understated. CUDA has been downloaded over 30 million times and has an ecosystem of roughly 3 million developers. It has gained significant acceptance within the deep learning community, is a more sought after skillset in job postings than its competitors, and is integrated into courses of many top universities, students of which then go to on to join many of Nvidia’s customers such as the hyperscalers and other enterprises.
Another open standard framework is OpenCL, first introduced in 2009 and initially developed by Apple but now managed by nonprofit Khronos Group, and contributed to by AMD, IBM, Intel, Nvidia and many others in the industry. OpenCL is open source and works across CPUs, GPUs, and FPGAs among other hardware accelerators. However it never seemed to get widespread adoption as its performance lags that of CUDA, and for AI and HPC only the best is acceptable. Further, all of the major deep learning frameworks such as Google’s TensorFlow, PyTorch and Microsoft CNTK support CUDA2, whereas currently the support for OpenCL is much more limited.

In addition to CUDA, perhaps the greatest source of sustainability for Nvidia is the software libraries they have built on top. The company broadly buckets these under CUDA-X, which is the label for its collection of libraries and software development kits (SDKs) that accelerate AI and HPC applications for a range of domains and end users. CUDA-X comprises of an ever-increasing number of libraries which capture the entire range of AI activities from data processing to inference, with the most popular being:
cuDNN, a library of highly tuned implementations for standard AI training functions (such as pooling and convulsion) so that AI frameworks such as TensorFlow and PyTorch don’t need to implement these themselves
Rapids, suite of SDKs for data scientists using Python to accelerate drug discovery, social connections, fraud detection and more
TensorRT, software for optimizing trained models for inference
All of these libraries have been downloaded millions of times, and ones like Rapids are currently being used in thousands of Github projects.
Given the diversity of AI use cases across industries, a one size fits all approach is far from optimal. To that end, Nvidia has created application-specific frameworks to accelerate developer productivity and address the common challenges of deploying AI within specific industries. These applications include Clara for healthcare, Isaac for robotics, Drive for auto, Aerial for telco and 5G, Maxine for video conferencing, Merlin for recommender systems, and Riva for conversational AI. These allow AI researchers and developers to just focus on coding, instead of worrying about setting up the software stack which is complicated and time consuming, in turn increasing the switching costs for Nvidia.
It’s important to note that the majority of Nvidia’s software kits are available for free. The vast majority of Nvidia’s revenue is from hardware sales, with the software freely provided as a differentiator that binds customers to the chips. However, the software philosophy is slowly being extended to the way to Nvidia monetises its hardware as well. In Part 1 I mentioned how on the consumer side Nvidia is monetising its GeForce cards in the cloud via GeForce Now. In data center, it has introduced DGX Foundry, a monthly subscription model for enterprises to get instant access to their powerful DGX systems. This is also paired with Nvidia Base Command, a cloud-hosted software solution that allows teams to manage the entire AI training process end-to-end and from anywhere. The biggest example of Nvidia monetising its software directly however is Omniverse, its real-time graphical collaboration platform used for both visual effects and simulations of “digital twins”, which is sold to enterprises as a server license with a per use fee (Omniverse and Auto will get a dedicated article in the future as these are very interesting growth options for Nvidia).
Finally, according to Jensen, AI at the edge will be an even bigger area of AI than in data centers, and Nvidia has a suite of software and hardware solutions to address this area as well. Nvidia’s Fleet Command is a cloud service that securely deploys, manages, and scales AI applications across distributed edge infrastructure, for example training an AI model in the cloud and then need to distribute it to edge servers, fleets of vehicles or IoT devices. This pairs with hardware like Nvidia Jetson, which are small high performance computers embedded in autonomous machines and vehicles.
While I’ve only touched upon the key elements of Nvidia’s software ecosystem, it’s pretty clear that the scope and depth of it is immense and is ever-increasing. With the company having more software engineers than hardware and significantly greater R&D budgets than its peers, this software advantage is likely to persist for a long time even if other players reduce the differential on the hardware side.
COMPETITIVE LANDSCAPE
Essentially the bear case arguments for Nvidia seem to be centered around three key points:
1) gaming (or crypto) cycle gluts on the consumer side which Nvidia is now going through
2) reliance on TSMC and the associated geopolitical risk (this one is rather binary as TSMC is a single point-of-failure for the entire world’s computing industry). I’ll address the recent China sales restrictions in the next piece on valuation but in short it would be prudent to remove all of the China sales from the data center segment going forward (c. $1.6-2bn dollars a year)
3) increasing competition it faces in the data center from a plethora of players
This third point is what I have spent some time exploring here given the data center business is now larger than gaming, and will be Nvidia’s most important segment going forward.
With the growing modularisation and outsourcing of large parts of the semiconductor supply chain, it has become increasingly easier to design and manufacture new chips (enabled in large part by TSMC’s fabrication prowess). As such there’s been a Cambrian explosion of parallel compute chip architectures trying to tackle the exponentially increasing requirements of AI models. This includes competition from established chip companies (AMD, Intel), hyperscalers (Google, Amazon), and startups (Cerebras, Graphcore, amongst many others). While for the foreesable future Nvidia and its GPUs seems to be the technology of choice for the vast majority of AI workloads, these competitors do pose a longer-term term threat to Nvidia’s market share.
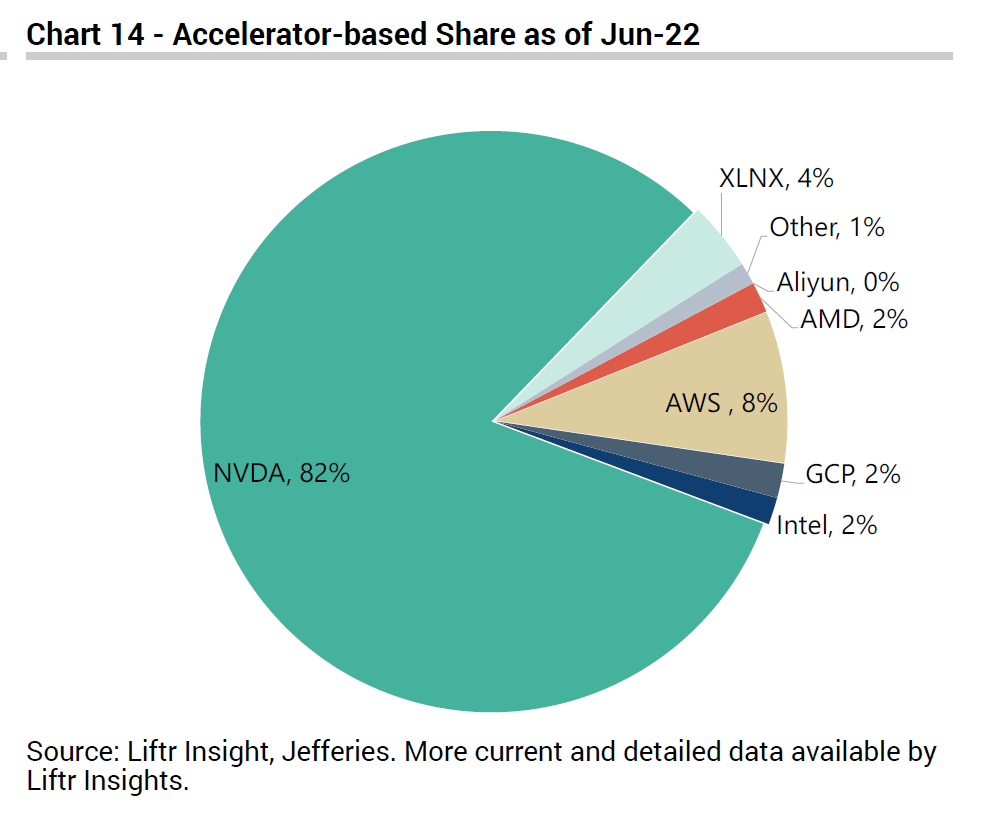
To level set, on the training side Nvidia has become the defacto standard with a near monopoly position. In inferencing, it has been gaining share by adapting its GPUs to be more flexible (e.g. mixed-precision formats, multi-instance partitioning, lighter-load A30/A10 chips, as well as TensorRT software). According to data from Jefferies (using Liftr as the underlying source), Nvidia’s share of accelerated instances across the major public cloud providers is over 80%3.
Its most direct competitors are the large chip vendors AMD (now including Xilinx) and Intel. Both are traditionally CPU companies who’ve been trying to make inroads in the GPU market. Intel’s attempts to break into the data center GPU market have been mainly through acquisitions, first with Nervana (acquired in 2016), and then later with Habana Labs (acquired in 2019). Both so far seem to have seen limited success, but Habana shows the most promise. Habana’s Gaudi2 chip for training and Greco chip for inferencing have supposedly leapfrogged Nvidia’s flagship A100, at least according to Intel’s internal benchmarking. Gaudi2 is built on the same 7nm process and roughly the same size die as the A100 but comes with with 2.45TB/s memory bandwidth compared to A100’s 2TB/s.
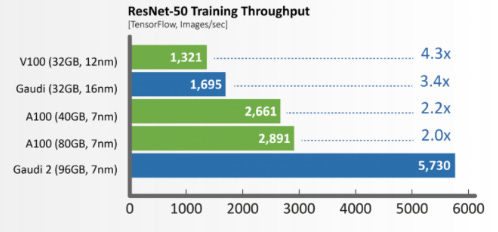
The commercial test cases for Gaudi2 so far are however limited as it’s only planned for launch later this year. Also while every chip vendor compares their newest chips to Nvidia’s A100, the A100 is already two years old. As discussed in Part 2, this year Nvidia announced the next gen Hopper H100, which with its multiple-fold improvement over the A100 will already far surpass Intel’s newest efforts. Intel is also planning on releasing its Ponte Vecchio GPU for AI and HPC workloads later this year, which makes me wonder if there is enough coherence in their approach. It will be interesting to watch their progress.
AMD, revitalised and focused under the helm of CEO Dr Lisa Su, is probably the more serious competitor to Nvidia. It already has significant experience in the consumer GPU market (#2 player with c. 20% market share), and it has an advantage over Nvidia in being able to offer an integrated data center hardware stack with its well-regarded, market share winning CPUs. Its Instinct line of data center GPUs is quickly catching up to Nvidia’s performance. Last year it launched its MI200 Instinct GPU based on TSMC’s 6nm process node, which claims to outperform the A100 along a number of vectors, including memory bandwidth (3.2TB/s vs 2TB/s).

The strength of AMD’s integrated approach is seen with some of its high profile wins. Its MI Instinct GPUs along with AMD CPUs are being adopted by the US Department of Energy for its 1.5 exaflops “Frontier” supercomputer at Oak Ridge National Laboratory, as well as the world’s fastest supercomputer the El Capitan. But similar to Intel’s newest chips, the MI200 has not yet had wide commercial tests as it only began its mainstream market deployment this year. Nvidia will soon begin deploying the superior H100, but AMD of course is not standing still and already planning for the MI300, which will reportedly be not a GPU, but an APU (Accelerated Processing Unit). APU is AMD’s term for hybrid processors which package a CPU and a GPU a single chip die, eliminating the data transfer and power inefficiencies that come with chip-to-chip connections. Nvidia’s entry into CPUs and things like its Grace-Hopper superchip sound like a direct response to AMD’s finely-tuned integration of its CPUs/GPUs and its single-die APU chips. Long story short, AMD is clipping at the heels of Nvidia in the race for bleeding edge chip dominance. Ultimately however, the software ecosystem is the critical piece where Intel and AMD both significantly lag Nvidia (more on this shortly).
With its recent Xilinx acquisition, AMD has also been adding FPGAs4 to their data center arsenal. FPGAs have the advantage of being reprogrammable even after their manufacture, and are considered extremely efficient for specific inferencing use cases. As we saw on the earlier chart, Xilinx chips have received some traction in the cloud market, accounting for about 4% of accelerated instances in public cloud providers, which will get added to AMD's own chips which account for an additional 2%. However Xilinx have a much bigger presence at the edge, where its FPGAs and SoCs get embedded in robotics, autonomous vehicles and IoT devices, a market in which Nvidia is also trying to make a big play. Xilinx is also strong in SmartNICs, which compete with Nvidia’s Bluefield DPUs. And AMD has further bolstered its presence in DPUs with a more recent acquisition of Pensando5.
So in summary, the three major chip companies are all making a play for various parts of the data center and edge computing ecosystem, and are increasingly converging across CPUs, accelerators, and networking. According to one expert, the future technology mix may shift in more diverse direction, and thus “whoever could offer the best compute portfolio across GPUs/CPUs/ASICs as a vertically integrated company going forward will have a longer-term advantage”.
On the hyperscalers side, Google and AWS have also been pushing their own in-house designed chips. Google has been investing in the Tensor Processing Units (TPUs), which are custom-designed ASICs6 that started out as a specialised AI inference processor but later became training processors. Its latest TPU v4 which was launched this year claims between a 1.05x to 1.6x speedup over the A100 based on MLPerf 2.0 tests (a respected industry benchmark).

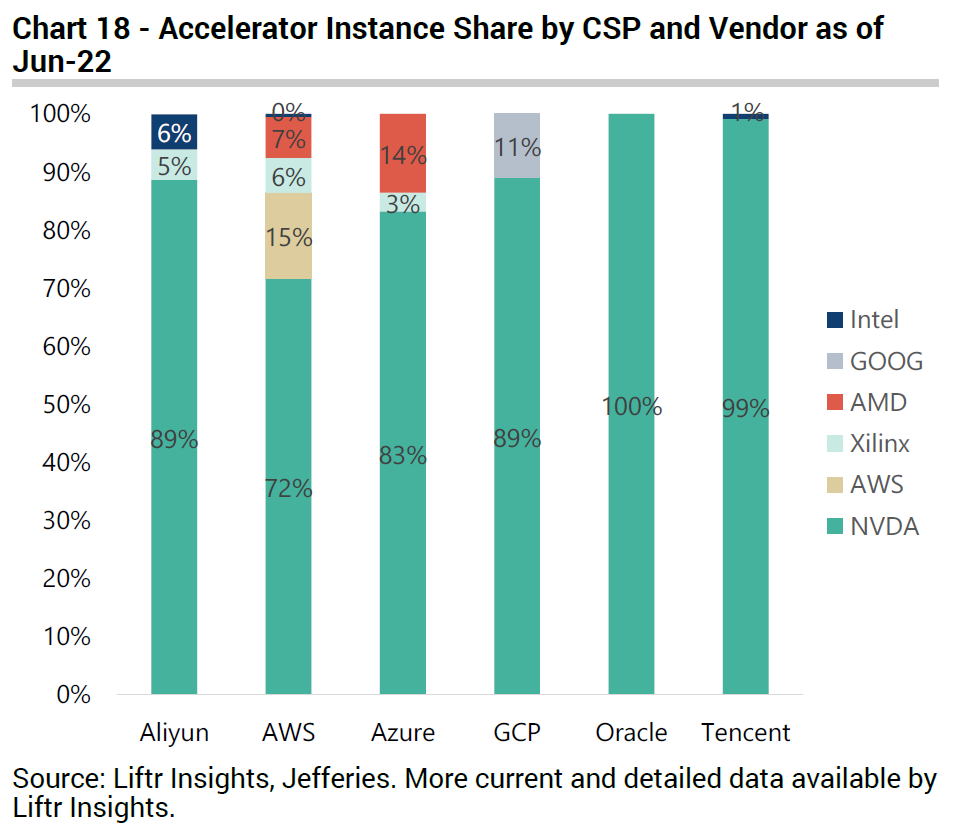
TPUs at this stage are predominantly being used for Google’s own internal purposes, things like YouTube and Search algorithms, Google Photos, AlphaGo. Increasingly however, they are also being used to enhance Google’s own cloud services - as shown below Google’s chips now account for about 11% of Google Cloud’s accelerated instances, with the rest still belonging to Nvidia. Given their presence is limited only to GCP, I am not too worried that they will pose a large threat to Nvidia's business. Further, TPUs are AI-focused chips that are optimised for Google’s TensorFlow framework, which may not be suitable for all other uses cases and AI frameworks like Nvidia GPUs are.
The TPUs do raise a larger question however around whether in the future specialised ASIC chips could take over most of the use cases that a general purpose GPU is currently used for. While ASICs can be extremely efficient at specific, singular use cases due to their high customizability, they take a long time to develop and are not easy to use. According to one expert, “programming them tends to be difficult, and they tend not come with the software…their software layer is just not mature and has a learning curve to it”. These factors have been a key source of friction to their growth, although new methods to speed up the ASIC production cycles can help improve their cost effectiveness.
AWS has also developed its own chips for inferencing (Inferentia launched in 2018) and training (Trainium launched 2020), mainly for the purpose of bringing down costs for its cloud customers. Inferentia seems to be the one that’s been pushed more significantly to AWS customers7. There has been some back and forth competition between AWS and Nvidia, with AWS claiming that Inferentia’s straight-out-of-the-box inferencing performance is better than Nvidia, while Nvidia’s response was it is significantly better once you optimise the workloads with its TensorRT and Triton inferencing software. Nonetheless, as we can see below, Inferentia’s share of AWS accelerated instances has increased over the last two years. AMD and Xilinx have also been winning some share, and as a result Nvidia’s AWS share has declined from over 80% two years ago to 70% today, which is its lowest share among all the hyperscalers (for Azure, GCP and Alibaba Cloud Nvidia’s share is in the 80-90% range - see above chart).

While AWS is still Nvidia’s single largest customer, the problem of course is that AWS is the largest cloud provider and whatever happens within its data centers may have a significant impact on Nvidia’s growth. AI inference is expected to be much larger than training in the future, and as we can see AWS is actively pushing to take share in this market with its own chips. The same may eventually happen on the training side as well with its Trainium chip.
All of the current hardware approaches to AI and HPC require stitching together large-scale clusters of processors, be it GPU or others, often in hundreds and sometimes thousands. The problem with this is that the moment data needs to go ‘off chip’ and travel through network switches and fiber optic cables, there is loss in efficiency and increased power requirements. There are decreasing marginal gains from every additional GPU. According to one expert, utilisation on some of these GPU-chained training systems is sometimes around 30-40% of their theoretical FLOPS capacity - i.e. rather inefficient. Many new companies are trying to figure out a different, more efficient way, to approach this computing problem. According to PitchBook US chip startups have received over $11bn in funding since 2012, so there are a lot of contenders. I thought I would just quickly touch upon two of the more promising ones.
Cerebras has received a lot of attention having raised over $700m in total funding, and labeling itself as the fastest AI processor in the world. Founded in 2015, its approach is to use a single, very large, wafer-scale integrated processor that includes compute, memory and interconnects all on one chip. Its second gen WSE2 AI system is 26 inches tall, has 850,000 cores (vs. A100’s ~7,000) and 2.6 trillion transistors (vs. A100’s 54bn). By having so much computing power and memory on a single chip, it is able to achieve insane bandwidth of 20 petabytes per second (i.e. 10,000x more bandwidth than A100’s 2TB/s). This is what the Cerebras WSE2 system looks like vs. the A100 - it’s an absolute Godzilla.

The Cerebras system is getting some early use cases in big pharma for drug discovery purposes, claiming GSK and AstraZeneca as some of its marquee clients. So why doesn’t everyone doing AI move their workloads to this sort of system? It’s a matter of cost efficiency. While the Nvidia A100 costs around $10,000, each Cerebras WSE system retails for $2-3m apiece, and is only available as part of a wider system which spans 15 of these rack units. Other than for enterprises running the most mammoth AI training exercises, it just won’t be economical or practical for the majority of customers running standard, simpler AI models. According to one expert, the Cerebras system will only really be appropriate for a small segment of the market:
“While the gigantic wafer is quite interesting, it is challenging to deploy in that you’ve got to have specially built water-cooled systems, you’ve got to have quite a bit of power to be able to deploy these, you’ve got to have pretty custom software work done, and so what I think all that means is you end up with a pretty small number of customers that can actually put this into production. I think it’s going to take a while for them to get to a large revenue ramp.”
Third Bridge expert call - former data center executive at Intel and Qualcomm
Graphcore is another high profile multi-billion dollar startup that is using wafer-on-wafer chip technology from TSMC that results in more power efficiency than Nvidia (Graphcore’s chips operate at 200W vs. Nvidia A100’s 400W). Interestingly its performance in the MLPerf industry benchmarks last year were quite bad, but it seems this year they managed to rack up a significant improvement largely driven by software optimisation. But according to one expert, he questions whether their performance is that much better than Nvidia to create the impetus to switch to their chips:
“Is Graphcore really that much better than Nvidia from a performance-per-dollar perspective? They published a number of benchmarks that show they are slightly better maybe than Nvidia, but not significantly, and so I think that’s probably an additional factor in the decision is just a, “If I’m going to bring on a new architecture, I need to see a bigger delta between what I have with Nvidia and whatever else I’m going to bring onto the market.”
Third Bridge expert call - former data center executive at Intel and Qualcomm
I think this question of whether the performance improvements or cost savings are worth taking the risk of moving to an untested architecture in a mass deployment setting will pervade all of these startup companies. Maybe some practitioners and researchers that are pushing for the complete bleeding edge will want the most innovative and efficient chips out there. But for the majority they know that Nvidia will reliably get the job done and will be the easiest to use.
Going back to the MLPerf benchmarks, in the 2022 round of training tests Nvidia’s widest versatility and hardware-software integration was on display as it was the only company to submit results for all of the training and inference tests using its two-year old A100s, and in turn winning the majority.
Additionally, according to SemiAnalysis, when it comes to the important metric of Total Cost of Operation (TCO), Nvidia still dominates. It’s constantly adapting its GPUs to be flexible enough to run a wide range of models and use cases, which is often what’s required when deploying AI in the real world:
“With multiple different model types from speech recognition to vision to recommendation models all working in tandem, having an accelerator that is best suited for just 1 model type is a sure fire way to bad TCO. In a data center, one of the most important metrics is utilization rates. Nvidia is the only company whose hardware can be used for data preparation, training, and inference. Many of these other companies are focusing on training and inference, or training alone.”
So despite all the emerging hardware competition, it seems that at least for the foreseeable future Nvidia’s GPUs will maintain their incumbency. But ultimately, it’s not just about the hardware, but also the software and ecosystem acceptance that comes with it, and here Nvidia has an undisputed advantage which creates a virtuous cycle with its hardware.
CUDA, as discussed earlier, is superior to the other major hardware programming language OpenCL in terms of performance and adoption, although its key disadvantage is lack of flexibility given it is tied exclusively to Nvidia GPUs. AMD also has its own Radeon Open Compute Platform (ROCm) which works with not only AMD GPUs but others as well, but so far it seems to have seen limited traction (evidenced by the fact that unlike Nvidia, you don’t ever see AMD talk about its developer ecosystem on earnings calls). AMD’s software approach also somewhat lacks coherence as for a long time it’s been pushing the OpenCL standard as well. There is no question that AMD is strong on the GPU front, but according to one expert it has consistently struggled to attract strong software talent and as such has significantly fallen behind Nvidia in this area.
Intel’s software platforms in the form of oneAPI and OpenVino also have the advantage of being hardware agnostic languages, however they are in a relatively early stage and one expert thinks that they are many years away from getting to CUDA’s level of depth. Google is developing its own open-sourced and hardware agnostic languages called JAX and Julia. Their weakness however is that they are based on Python, which is not as optimised for high performance computing as C++ on which CUDA is primarily based. They are also more focused on AI/ML, whereas CUDA is geared towards all sorts of HPC use cases. Given the history of poor adoption of open source standards, some experts think that these competing languages will never be able to replace CUDA entirely, and in fact all them still offer CUDA integration.
Over the long-term, if AI/HPC technology moves in a more flexible, hardware agnostic direction, CUDA’s dominance may diminish at the expense of some of these subscale platforms. At least for the foreseeable future however, it doesn’t seem like there are any competing ecosystems that could meaningfully threaten CUDA’s lock-in.
Nvidia is also significantly ahead in customizing higher level libraries for specific verticals and industries. Nvidia’s significantly higher R&D budgets (as a result of its superior scale) allows the company to reinvest more in its software stack than its peers, strengthening the virtuous cycle. According to one expert who used to work at Nvidia:
“For every single application, like NAMD [computer software for molecular dynamics simulation] or any single one, there’s a team of Nvidia people, more than three people, who are working to accelerate their particular workload. I don’t know that the other firms are giving it that same kind of individualised effort.”
Third Bridge expert call - former Nvidia executive
The same expert succinctly summarises Nvidia’s software lead:
“The Nvidia AI stack is the most fleshed out one on the industry, which is why it’s the one that gets used the most, and it’s directly correlated with the sale of the hardware. That makes it sticky as well. As people get more used to the software, they just continue using the Nvidia hardware….I don’t know that I’ve seen similar things with other providers like AMD or Intel. I haven’t been able to see a one-stop-shop”
Third Bridge expert call - former Nvidia executive
Finally, going back to the point on costs, SemiAnalysis makes the point of how software is a key part of Nvidia’s TCO advantage:
“That software stack is incredibly important as it represents the majority of a company’s costs for all but the largest operators. Having developers be able to easily tweak models, deploy, test, and iterate is critical to reducing the development costs. The combo of software flexibility, development cost, and higher utilization rates leads to Nvidia still holding the TCO crown.”
Perhaps the biggest long-term risk is an "unknown unknown." Nvidia has obviously put most of its eggs in the GPU basket, however with the frenzied pace of innovation and technological advancement in the space, there is always risk of an unexpected discontinuous change that sends the industry on a different path. It’s hard to predict where technology trends will go, but possible risks include a new chip architecture breakthrough that is decisively superior to GPUs, inferencing or edge computing (where GPUs are less used) backward integrating into training, or specialised chips getting cheap enough and easy to use to the point of taking over most of the jobs of a general purpose GPU.
So far over Nvidia’s almost 30 year history it has been able to continuously reinvent itself and adapt to the changing, complex landscape. That doesn’t mean they haven’t had major missteps along the way. If you listen to the history of Nvidia on the Acquired podcast, you realise there were numerous near-death moments and fundamental miscalculations that they made about the market. However, they’ve always been able to course correct and survive, and as a result the company today looks very different to what it started out as. Other long-lived tech companies such as AMD, Microsoft and Apple have all had to transform in ways that couldn’t have been known ahead of time. A long-term bull thesis would need to believe that Nvidia management will continue to execute well and pivot the business successfully. So far the track record suggests they can, and it helps when you have a bold and visionary founder-operator at the helm.
SUMMARY
As is probably clear from the last two articles, there is just so much going on with Nvidia in its data center segment. It is investing across multiple hardware technologies, software platforms and domain-specific applications. It is easy to get lost in the constant stream of product announcements, speeds and specs, and obscure computer lingo. The thesis for long-term bulls however can simply be summarised as this: AI will dominate all industries in the future and require GPUs for training and inference. Nvidia’s GPU technology with its complete software stack will be the foundations of this AI future, and will be deployed in data centers, on-premise in the enterprise, and at the edge.
However, the risks from competition and potential disruptive trends also cannot be ignored. While Nvidia has so far been consistently a step ahead in terms hardware performance and flexibility, the playing field is being equalised by the plethora of competition looking to chip away at this attractive market. Nvidia’s long-developed software ecosystem is however currently unmatched and creates a substantial moat around its hardware, at least for the foreseeable future.
It would be prudent to assume that over the medium to long term Nvidia’s dominant market share of accelerators will probably shrink somewhat, and there is already evidence of this. After all, when you start off with 90%+ market share, the only way to go is really down. Some experts think that it may end up closer to 70% in the next five years. Shrinking market share should not be confused with declining revenue but, as the whole segment is still growing rapidly. For example, some estimates are that accelerated servers account for only about 10% of total servers in the cloud. Assuming that the demand for AI and HPC workloads continues to be robust in the future, this would suggest that a large runway still remains for Nvidia’s data center segment.
In the next article I will come back to on what this means for Nvidia’s valuation and forecast returns.
Some good sources that I used for researching this piece:
SemiAnalysis:
Nvidia In The Hot Seat? Intel Habana, Graphcore, Google TPU, and Nvidia A100 Compared In AI Training
How Nvidia’s Empire Could Be Eroded - Intel Network And Edge Has The Playbook
Fabricated Knowledge - NVLink/Switch and Platform Wars
Jensen’s AI keynote at MSOE (YouTube video)
Asianometry’s YouTube videos on Nvidia:
Acquired podcast episodes on Nvidia, part one and part two
Liberty RPF’s newsletter Liberty’s Highlights has great ongoing coverage of Nvidia
The Razor’s Edge podcast The Future of Compute series - part one, part two, part three
Mike Kytka (Money Flow Research)’s great deep dives into Nvidia here and here
The way to think about these interactions is that a researcher may use TensorFlow or PyTorch libraries to build an AI/ML model, and CUDA would take that TensorFlow/PyTorch code and translate it to run on GPUs. Over 90% of ML models globally use TensorFlow or PyTorch as they abstract away the GPUs.
According to the company, hyperscalers probably account for about half of Nvidia’s data center revenue, with the rest being enterprise. This 80% figure is its share only across the hyperscalers and therefore isn’t reflective of Nvidia’s actual market share across the data center segment, but nonetheless it is would still be almost complete Nvidia dominance
FPGA stands for field programmable gate array, which is type of ASIC (see footnote 6) that can be programmed after manufacturing, even after the hardware is already in the field.
More broadly, there are quite a few competing DPU products out there, with Broadcom, Marvell, AMD/Xilinx all having a strong positions in this segment, meaning we shouldn’t be expecting the Nvidia/Mellanox combo to be taking over the data center any time soon.
ASIC stands for application-specific integrated circuit, which is a highly customized chip for a particular use, rather than general-purpose use like a GPU
The way AWS positions Inferentia vs. Nvidia’s chips is that Inferentia is preferred for recommendation engines, image and video analysis, advanced text analytics, advanced fraud detection, translation etc - all the classic inferencing use cases, while Nvidia is preferred for deep learning training, HPC, scientific research, as well as more advanced inferencing applications.
Amazing report. As a graphics programmer Ican't find any errors in your technical descriptions. Except for the typo in Pensando but that's mostly because I'm a Spanish speaker. Thanks for sharing!!
Excellent work, friend!