
Nvidia - Part 2: "The Data Center is the New Computing Unit"
Deep dive on Nvidia

At Nvidia's 2017 investor day, in a comment referring to the company's investments in artificial intelligence, CEO Jensen Huang made one of the boldest and honest statements I've ever heard senior management of a company make in public - "This is all going to work out great, or terribly for us, because we're all-in." Well, so far Nvidia’s transition to AI has worked out better than just about anyone imagined.
In Part 1 I covered how Nvidia evolved from being just a supplier of PC graphics to a full-stack computing company enabling workloads that power the modern world, namely AI and high-performance computing (HPC). AI requires mountains of data to train and refine models, to the point where it is impractical to run them on just one one computer or a cluster of servers. These workloads are so immense that they require data center-scale computing. Nvidia is framing the basic unit of compute as the data center itself, and its ambitions are to take full control of them from top to bottom. These next two articles will be all about Nvidia’s Data Center segment, which is now undoubtedly its most important and highest growth business. It is also facing some interesting competitive dynamics which I will discuss at length as they cannot be ignored by investors.
I was originally going to do one article on Data Center, however I have decided to split it into two parts as there was too much to cover:
Part 2: Data Center: Overview of AI workloads - training and inference, and Nvidia’s GPU technology in this segment
Part 3: Data Center: Nvidia’s expansion beyond GPUs, its full-stack computing approach including CUDA and software applications, and competitive dynamics
Part 4: New growth segments - Omniverse and Auto
Part 5: Valuation and summary
Disclaimer: I am long Nvidia, and this article is not investment advice nor a substitute for your own due diligence. The objective of this article is to help formalise my thinking and enhance my understanding of the business, and hopefully provide some interesting insights at the same time.

DATA CENTER SEGMENT (40% OF REVENUE)
Nvidia’s Data Center segment sells hardware and increasingly software to enable AI workloads and HPC to clients ranging from hyperscale cloud providers (AWS, Microsoft, Google, Alibaba etc), enterprise customers, and research institutions that require supercomputers for complex scientific research. This segment has been growing revenue at a CAGR of 66% from FY17-22, currently standing at $10.6bn, or 40% of the group’s total revenue. It will likely overtake Gaming this year to be Nvidia’s largest segment. A few years ago this segment was predominantly serving HPC use cases - think scientific supercomputers for research institutions, universities, labs and enterprise. However with the explosion of AI in recent years, the focus has completely shifted to serving this high growth area, and as such AI is now the key driver (and AI and HPC themselves are increasingly converging).

To understand why AI requires data center scale computing with GPU accelerators, it’s worth understanding a bit about the deep learning methods that underpin it.
Machine learning
A broad definition of artificial intelligence is any intelligence demonstrated by machines as opposed to natural intelligence. Machine learning is a highly statistical approach to creating artificial intelligence. It involves the use of algorithms to parse and learn from large datasets, using the results to improve the algorithm, until accurate predictions or classifications can be made based on new data. A simple recommendation system like that on a music streaming service is an example of a machine learning algorithm.
In recent years, a subset of machine learning known as deep learning has been garnering steam and igniting significant interest in AI. Deep learning is about using neural networks - complex, layered structures resembling the human brain - to train machines to think and make predictions on their own instead of giving them explicit instructions. This leads to a learning system that’s far more capable than that of standard machine learning models, such as Google’s AlphaGo which was the first computer program to defeat a professional human Go player. Up until the last decade, neural networks have been basically impractical to run due to the immense amount of computing power and data required. However, this all changed with the invent of GPU accelerated computing.
“Training” neural networks
At a very high level, a neural network is a series of algorithms that aim to recognise relationships in a set of data through a process that mimics the way the human brain operates. The classic diagram depicting a neural network is a series of circles connected with arrows and lines, like this:

Each circle represents a “neuron", which is basically a calculator that takes in inputs and produces an output. The outputs of some neurons can also become the inputs to others, forming a complex network many layers deep. Often however, we may not want to treat each input as equal, so we would manipulate their weights in order to have the neuron produce more accurate outcomes. On top of that, we can change the “bias” of each neuron, or the rules or thresholds with which it calculates the output. This process of tweaking these variables - the weights and biases - in the network is called “training” the network, or in essence getting it do whatever complex task you want it to do as accurately as possible, eg. recognising handwriting or speech, or driving a car without crashing into obstacles. During training, a set of data representing real-world examples of the type of phenomenon we would like the network to recognize is "fed into" the network. For example, a single handwritten character can involve hundreds of pixels, or distinct inputs, which can be tuned over the course of many repetitions until the algorithm can accurately predict the result against the known training dataset. We can imagine how tuning so many variables can quickly become an insanely complex task. Complex deep learning models can have billions of weights with potentially trillions of connections between them.
The punchline is this - working through these large neural models is effectively a process of multiplication of large data matrices, each of which can be done independently. They are “embarrassingly parallel”. Due to their ability to take in massive amounts of data and crunch through it in parallel, GPUs, and in particular Nvidia GPUs, are the gold standard in training neural networks. Virtually every company, institution, and researcher exploring artificial intelligence uses Nvidia GPUs of some kind on the training front.
Deep learning models have been evolving to take advantage of GPU hardware, and GPUs have been evolving to accelerate the ever-increasing models in a positive feedback loop. The below chart lays out the size of some of today’s largest models in terms of billions of weights, or parameters. At the top of the chart is the massive Microsoft-Nvidia developed natural language processing model Megatron-Turing NLG 530B, which uses 530 billion parameters. It is trained on massive supercomputing clusters like Nvidia Selene, which has thousands of GPUs connected together with high-speed interconnects. Models however, are already reaching the size of trillions of parameters, such as Google’s Switch Transformer which has 1.6 trillion parameters. As we’ll see later, Nvidia is gearing up its next generation of data center technology to be capable of efficiently running trillion parameter models.

As an another notable example of an AI computing system, last year Facebook/Meta announced its new AI Research Supercluster (RCS), which claims to be currently the fastest AI supercomputer in the word. It would contain ~6,100 Nvidia A100 GPUs, and could deliver 1.9K petaflops (or 1.9 exaflops) of performance (petaflops is scientific computer lingo for processing speed - it stands for floating point operations per second). For context, the Fugaku research supercomputer in Japan, currently regarded as the fastest in the world, has a max performance level of 2.15 exaflops. This would mean that Meta’s RCS could train a model with tens of billions of parameters in about three weeks, which is considered a short training period. Research by OpenAI suggests that the amount of compute used for training AI models doubles every 3 months, so there is an insatiable appetite for larger computing systems. As such, Meta plans to expand the RCS later this year to 16,000 Nvidia GPUs, or 5 exaflops.
“Inferencing” neural networks - using the networks to accomplish a task
After a neural network is trained on a known dataset, the next step is to actually use it with input data that is unknown. This is known as inference, where new, real-world data is put through the trained model to "infer" an answer in real-time. There is a wide variety of deep learning use cases, which is leading to its adoption in just about every industry:

Inferencing requires a small fraction of the processing power of training. So while training models is all about heavy usage of GPUs, in inferencing the technology usage is much more diverse, consisting of CPUs, ASICs, FPGAs, and GPUs. This is because the key consideration for inferencing isn’t usually maximum throughput (which is what GPUs are traditionally good at), but latency, power efficiency, and cost, which means other chips may be more efficient than GPUs in doing the task. This is an important point for Nvidia investors to understand, as the dominant segment of the AI opportunity going forward is likely to be inferencing. McKinsey has predicted that by 2025 the opportunity for AI inferencing hardware in the data center will be 2x larger than that for AI training hardware, and, in edge device deployments it will be 3x larger.
Many industry observers came to believe that Nvidia’s technology was not suited for AI inferencing. And a few years ago that was true - Nvidia had little presence in inferencing in either the data center or the edge. However, over the last few years developing products and solutions to cater to inferencing has been a top priority for the company. On the hardware side, its current generation of data center GPUs like the A100 are optimised for inferencing by allowing a range of floating point calculations at lower precision levels (which is appropriate when speed and power efficiency is a priority), as well as allowing partitioning of the GPU into smaller instances where different neural networks can be run in each instance (Multi-Instance GPUs). It also sells lower powered, cheaper versions of its cards such as the A30 and the A40, which may be more appropriate for lighter weight inferencing work. Similarly on the software side it has developed a range of solutions to improve inferencing performance, such as the Triton Inferencing Server and Tensor RT, both software solutions that help optimise deep learning models for inferencing on GPUs and CPUs.
By integrating across both hardware and software, Nvidia has been able to deliver strong inferencing performance as shown in external industry benchmarks such as MLPerf below (this is a well-respected industry benchmark which Nvidia likes to boast, however it seems that not all the players partake in this test, for whatever reason). Its smaller edge solutions like the AGX Orin box for auto is also seeing strong recognition.
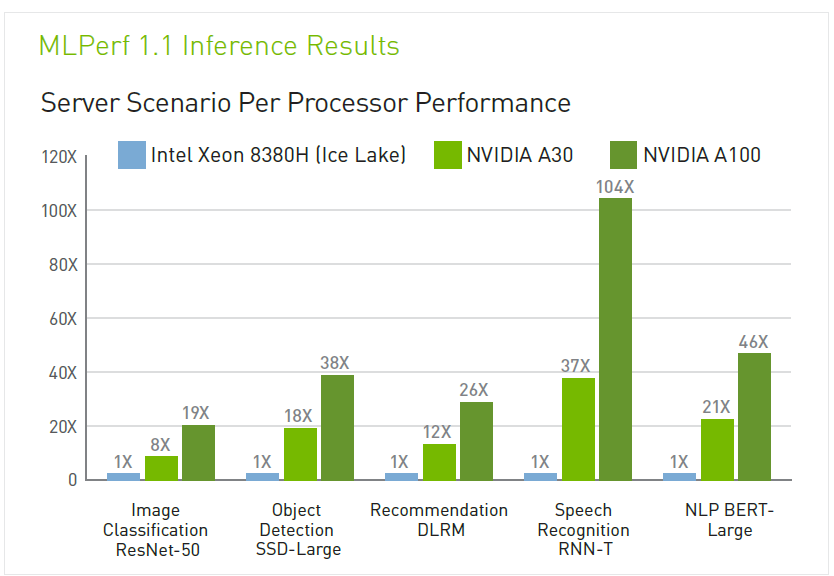
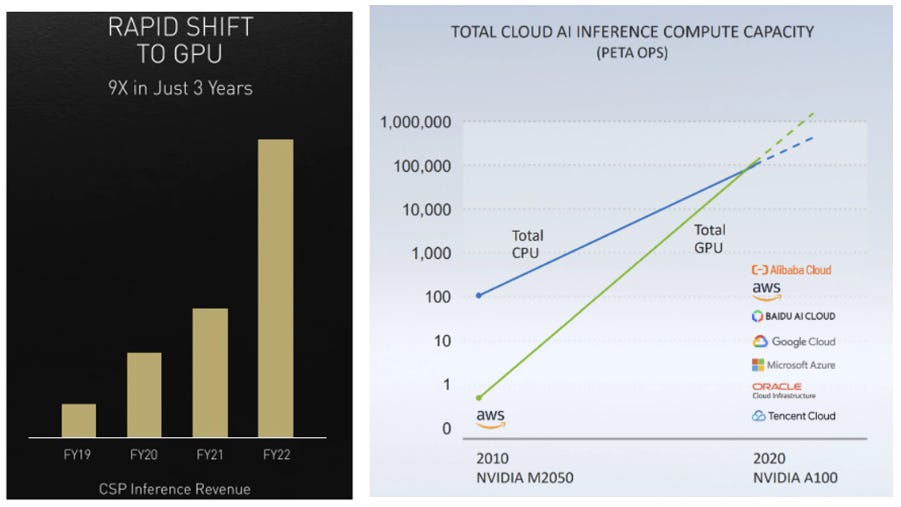
More importantly, the results of the company’s efforts can be seen in Nvidia’s large growth in inferencing revenue as shown in the chart below left. Unhelpfully, no actual dollar revenue are disclosed, but it is clear that its inferencing revenue is growing at a faster rate than the whole Data Center segment. In 2020 Nvidia also stated that it believes that Nvidia GPU inference compute capacity exceeded that of all cloud CPUs (below right), and at that point it predicted that in 2 to 3 years Nvidia GPUs would represent 90% of the total cloud inference compute.
These data points are difficult to validate, but without a doubt Nvidia is getting wide adoption in the inferencing market. Based on various publicly announced collaborations, below we see how Nvidia’s AI platform is being used across a range of industries and use cases including predictive healthcare, online product and content recommendations, voice-based search, contact center automation, fraud detection, and others, with deployments across on-premise, data center, and the edge.

Of course all of this is best implemented in data center infrastructure, where workloads can be efficiently scaled-up or scaled-out across servers in a disaggregated manner. The data center can be configured to act like one unified computing unit to train giant neural network models, or can be split across multiple customers with smaller workloads who may be unable to justify the high capital cost requirements on their own.
Market share
While it is difficult to get accurate market share data in this space, the handful of studies that are available show complete Nvidia dominance. Though a bit dated, the below data from Liftr Cloud Insights shows Nvidia having nearly a monopoly position on accelerators used by the hyperscalers.

Similarly a more recent study by Omdia had Nvidia’s share of AI processing in the data center at over 80%, followed by Xillinx’s FPGA products (now acquired by AMD), Google with its Tensor Processing Unit, while Intel finished fourth with its Habana AI accelerators and its FPGAs. AMD ranked fifth with AI ASSPs for cloud and data center.
So in summary, Nvidia naturally dominates compute-intensive AI training workloads, and by innovating through the full stack from hardware to software, Nvidia seems to have carved out a role for itself in the inferencing market as well. For the foreseeable future Nvidia’s dominant position looks assured. As we’ll explore in the next article however, the competitive landscape is dynamic and a variety of players are clipping at their heels.
NVIDIA DATA CENTER GPUs
Just like with the consumer GPUs, Nvidia’s data center GPUs come in 2 year cycles, with every generation capitalising on smaller TSMC process nodes, squeezing more transistors onto the wafer, increasing the core count, and thus processing power.

When looking at this stuff it’s easy to get lost in the arcane world of speeds and specs, and for those who want to dive deeper into the technical aspects I’ve included a good list of resources at the end. Ultimately however, what’s important to understand is that GPUs need to be able to process a large amount of data, and since the actual computations that they’re doing in deep learning models are quite simple, the key measure of performance becomes the memory bandwidth - how much and how quickly data is moved around between the cores. This is why we constantly see Nvidia and its peers talk about memory bandwidth. Its current Ampere generation A100 GPU (launched in 2020) based on TSMC’s 7nm process node claimed to have the world’s fastest memory bandwidth at over 2 terabytes per second (TB/s) with a massive 80GB of onboard memory. This is twice the memory bandwidth of Nvidia’s top of the line consumer graphics card GeForce RTX 3090 Ti. It also comes at a much heftier price point of $10K. For those who like to geek out about this stuff, I recommend watching this awesome video of a home test of the A100 GPU.
The other key theme is that with the newer generations of chips, Nvidia has been innovating around other architectural choices which optimise more for AI and machine learning rather than standard HPC. In Ampere’s predecessor, Volta, Nvidia introduced the first generation of Tensor Cores - a computational unit designed specifically for deep learning. Tensor Cores are are able to conduct matrix multiplication at a much faster rate than Nvidia’s normal cores (called CUDA cores) at a cost to accuracy, however this is more fit-for-purpose for deep learning models. These same Tensor Cores are also used in Nvidia consumer GeForce cards for the AI-upscaling feature DLSS as discussed in Part 1.
While the prior Volta V100 generation was itself an extremely strong product, Ampere brought a massive performance uplift in performance, for example a 6/7x increase in performance for training/inferencing of the BERT natural language processing language model (below). This multiple-fold improvement was produced despite the transistor budget not increasing by anywhere near the same amount. The reason for this was architectural innovations around things like precision formats and sparse matrix acceleration1 that enabled the performance of AI workloads to be disproportionately boosted. Also the aforementioned partitioning feature, MIG, allowed for the GPU to be subdivided and used in smaller instances, creating one unified, flexible architecture for both heavy-duty training workloads and more light-weight, smaller inference workloads.


Nvidia sells its GPUs standalone, but it also sells them as part a fully integrated AI system/server called DGX. The DGX comprises of 8xA100 GPUs connected with nine Mellanox interconnects, two AMD CPUs, and six Nvidia NVSwitches, which allows the GPUs to transmit data to each other at incredibly high speeds. This can be treated as a single powerhouse easy-to-deploy computing unit. Meta is using 760 of these DGX systems in the aforementioned RCS supercomputer. The DGX system or some configuration of it has been adopted by the majority of the hyperscalers and data center providers to offer customers accelerated cloud computing for AI, including Microsoft Azure, Google Cloud, Alibaba Cloud, Equinix, Digital Realty, Dell, Cisco, and Pure Storage,
The Ampere chips have been very successful, with the company saying they’ve had the fastest ramp of any data center GPU in its history (just like in its Gaming segment). Despite these still being in their early days, in the world of bleeding edge chips the technological boundary needs to be constantly pushed. At the end of 2021, a year and half after the launch of the Ampere, AMD announced its MI200 GPU based on TSMC’s 6nm process node, which outperforms the A100 along a number of vectors including memory bandwidth (3.2TB/s). The MI200 is however not yet in wide deployment, only being used in a handful of supercomputers in research labs.
To cement its position at the top, at this year’s GTC event Nvidia announced its next gen Hopper architecture, described as its “largest generational leap ever”. The H100 GPU, produced on TSMC’s 4nm process node, crams 80bn transistors (vs. Ampere’s 54bn), and has 4TB/s of memory bandwidth (vs. Ampere’s 2TB/s). That is a massive amount of throughput. According to the company, twenty of these chips can sustain the entire of the world’s internet traffic at a point in time. It has a bunch of other innovations specifically optimised for AI2, which when accumulated result in the Hopper producing performance multiples times higher than that of the Ampere and AMD’s GPUs. With the Hopper, training of large models can be reduced from weeks to days, and when combining several of the H100s in a DGX system, it can comfortably handle the largest neural models of today with trillions of parameters.


Of course, everything in technology is completely modular and scalable. Nvidia can combine 8 of the H100 GPUs in a DGX system, and it can combine 20-140 of these DGX systems in a turnkey data center platform called a DGX SuperPOd, and then further yet, it is planning on combining 16 of the DGX SuperPODs to create the Nvidia “Eos” supercomputer - expected to be the world’s fastest AI system. Altogether the Eos will have 4,608 H100 GPUs producing 18 exaflops of performance, far surpassing the 5K petaflops of Meta’s RCS supercomputer mentioned earlier in its maximum deployment. The Eos will be an important step in fueling the work of researchers advancing climate science, digital biology and the future of AI.
So what does all of this continuously increasing GPU acceleration mean? By investing in more GPUs, enterprises and cloud providers are able to reap efficiency gains in AI training, inferencing, and analytics-type workloads. Whereas previously you may have needed a large number of CPUs or servers in a data center to run a workload, these can be replaced with just one or a handful of GPUs. And as we’ve seen, every generation of Nvidia GPUs produces a leap in performance over the previous, which means by upgrading you could generate significant savings in processing time, equipment, space and energy. Nvidia makes this very clear with the below example: an $11m data center using 50 of the older Volta-generation DGX system for training and 600 CPUs for inferencing using 630kW of power could be replaced with a $1m setup of 5 of the newer A100 DGX systems for training and inferencing (eliminating all of the additional CPUs) at 28kW of power. This underscores the company’s motto: “the more you buy, the more you save”.


As such, training costs for AI models are continuously coming down, as shown in the ARK analysis above. There are some interesting implications from all of this. The first, is that it is fair to ask to what extent GPUs can replace CPUs. No doubt Nvidia has been claiming an increasing amount of the heavy duty data center workloads that traditionally Intel would have handled with its general purpose x86 processors, which is part of the pressure that Intel as a company is feeling. However, the second key point is this: by continuously producing efficiency gains, GPUs are not reducing the overall demand for hardware (assuming there is only some fixed quantum of work), but are adding to it by enabling larger and larger amounts of AI workloads and thus spurring more consumption. As described above, CPUs are working in tandem with GPUs in DGX-type systems, so as Nvidia enables the AI market to grow, this will benefit all chip and hardware providers, including Nvidia, AMD, Intel, and a host of emerging players.
In the next article I will explore Nvidia’s expansion beyond the GPU into other data center chips (DPUs, CPUs), as well as its all-important software moat in the form of CUDA and its full-stack AI applications. I will also explore the competitive dynamics as Nvidia is facing competition from a variety of players looking to make inroads on this highly attractive data center segment.
SUMMARY
A quick summary of the key takeaways from this article:
Nvidia’s GPU ecosystem dominates AI training workloads, however the technology use in the much larger AI inferencing segment is more diverse. Nonetheless, Nvidia has been able to adapt its GPUs and integrate software solutions to carve out a position for itself in the inferencing market
With every generation of its data center GPUs, Nvidia has been innovating around architectural choices which optimise more for AI and machine learning rather than standard HPC (e.g. mixed-precision formats, sparse matrix calculations, multi-instance partitioning etc). This has driven performance improvements well beyond just what’s available by increasing transistor density
The Ampere A100 GPUs have seen the fastest ramp of any of Nvidia’s data center GPUs in its history, and it’s still in its early days. The envelope needs to be constantly pushed however, and the newly announced Hopper H100 GPUs will see a further multiple-fold improvement and cement Nvidia’s chips as the most powerful in the world, putting it well ahead of competing GPUs like AMD’s newest MI200
By continuously bringing down the costs of running AI workloads through accelerated computing in the data center, Nvidia has been enabling the AI market to grow through increased consumption, which has benefited not just GPUs but all data center chip and hardware providers
Thank you for reading and hopefully you found the article helpful. I welcome all feedback, good or bad, as it helps me improve and clarifies my thinking. Please leave a comment below or on Twitter (@punchcardinvest).
If you like this sort of content please subscribe below for more.
For further reading / info on Nvidia and the industry:
The Next Platform is an excellent source of insightful articles on all things computing, GPUs, and networking:
Acquired podcast episodes on Nvidia, part one and part two
Asianometry’s YouTube videos on Nvidia:
Stratechery articles:
Awesome YouTube video from Linus Tech Tips home testing the A100 GPU
Liberty RPF’s newsletter Liberty’s Highlights has great ongoing coverage of Nvidia
Nvidia company presentations and materials:
The Razor’s Edge podcast The Future of Compute series - part one, part two, part three
Nvidia’s third generation of Tensor Cores were designed to allow automatic conversion to a ‘sparse’ network structure, which allows for double the performance over dense networks. It takes advantage of the fact that most neural networks have a lot of weights/data points that are zero or close to zero. By zeroing all of these out and then retraining that network, the result is that the network can be compressed two to one. Nvidia has effectively created an automatic pruning technique that reduces the density of the matrix by half without any loss in effectiveness or accuracy. By skipping the zeros, the Tensor Core unit can do twice the floating point or integer math than it would have done with the denser matrix.
For those interested in the technical aspects, I recommend reading Next Platform’s deep dive on the Hopper architecture (see list of resources above). The list of new features include a capability to handle new lower precision-type formats (FP8), a new Transformer Engine, 2nd generation MIG technology, and DPX instruction sets to accelerate dynamic programming used in areas such as robotics and healthcare.
Fantastic article. Really helped me to learn more about NVIDA and data centers in general. You strike a fine balance between being concise and diving deep, where it is needed.
These have been excellent! Great work and thank you for sharing! Looking forward to the next parts!