


AMD - Investment Notes

Hello friends,
Quick side note - for those who use Twitter, please follow me on my new account @punchycapital. My original Punch Card Investor account was unfortunately hacked a few weeks ago and has been deactivated. Twitter seems to be becoming a bit more of an unstable place of late, and as such I am grateful to have a few thousand subscribers here on Substack that I can stay directly connected with. Thank you 🙏 And on with the show.
Through my work on Nvidia last year I spent some time looking into AMD, and eventually started a position in it. I believe that both of these companies are well positioned to be winners in the rapid rise in demand for computing and high performance workloads, namely AI.
I’ve titled this piece ‘Investment Notes’ as it’s really focusing more on what I think are the key points of the evaluation - the thesis, views on value/returns, and risks. For those who want to dive deeper into the company and its history, its products and other technical explanations, I included a list of good resources at the end. I’ll also end up referring to my Nvidia pieces a bit given the large overlap between the companies.
Investment thesis
Successful technological and strategic bets have set AMD apart from key competitors (chiplet architecture, advanced 3D packaging, modularity and adaptability in chip design, strong TSMC partnership for leading edge process nodes)
Will continue to take share from Intel particularly in data center CPUs, at least for the next three years, and quite possibly longer
Wide portfolio of technologies including CPUs, GPUs, FPGAs, DPUs and network chips, and ability to combine these in various combinations. This positions AMD well for a future that is heading in a heterogenous direction - different chips for different use cases in different locations - i.e. what AMD calls ‘pervasive AI’
Valuation - nothing more fun than when the stock just rips for seemingly no reason right before you publish your article. Post the 20%+ rally in the last week, at $97 per share it is trading at 32x fwd P/E, certainly not as cheap as the low 20s a month or two ago, but still lower than its longer-term averages (high 30s). From this price I believe you are looking at five year IRRs of around 10%, which assumes 1) more conservative growth projections than the company’s long-term plan, 2) multiple compression to 20x FCF, and 3) fully baked-in SBC. At $80 per share the IRRs are closer to 15%
Bear case/risks
I wouldn’t characterize AMD’s moat as a deep one. Despite their early lead in innovations such as chiplets and advanced 3D packaging, none of these ideas are exclusive to AMD. The whole industry is moving towards these types of designs in an effort to extend Moore’s Law, aided by the key participants in the semis supply chain such as TSMC (fabs), OSATs and EDA vendors. AMD has to keep running the innovation/IP treadmill to stay ahead
Intel gets revitalised under highly regarded CEO Pat Gelsinger and catches up to TSMC in leading edge chip fabrication by 2025/26, neutralising AMD’s performance advantage and growth
AMD fails to take any share from Nvidia in data center GPUs/accelerators, a massively important market given the demand for AI and HPC
AMD fails to make any meaningful progress on the software side, one of its key longstanding weaknesses against Nvidia

Company Overview
AMD is a fabless chip designer specialising predominantly in CPUs, but with a growing presence in GPUs, and a leading presence in FPGAs through its 2022 acquisition of Xilinx. In FY22 it earned revenues of $23.6bn across four segments of its operations:
Client (26% of FY22 revenue) - consumer desktop and notebook CPUs, and commercial workstations. The product range here consists primarily of AMD’s Ryzen series of CPUs. This segment has been going through recent weakness due to macro and aggressive pricing actions by Intel, resulting in revenue and margin decline
Data Center (26% of FY22 revenue) - server CPUs, server GPUs, networking solutions (smartNICs and DPUs), plus datacenter FPGAs - i.e. a complete suite of data center technologies. This segment saw massive growth of 64% in FY22 - this is now very clearly the growth engine of the group. On the CPU side the products comprise largely of the EPYC Series processors, with the latest EPYC 4 (“Genoa”), powered by AMD’s Zen4 core architecture launched in late 2022
Gaming (29% of FY22 revenue) - gaming GPUs and console business. The product range here includes the Radeon series of graphics cards where it plays a distant second to Nvidia’s GeForce. AMD also powers Xbox and Playstation consoles with its SoCs, a segment it refers to as Semi-Custom. The strength of the console business has been helping offset the decline in the desktop PC market in FY22
Embedded (19% of FY22 revenue) - this is largely the core Xilinx business (non-data center portion) plus AMD’s existing embedded business. This segment comprises predominantly of FPGA chips for all use cases that sit outside of the data center - edge computing, industrial, autonomous vehicles, telecommunications, storage and security etc. Currently the second most important segment to the group from a growth perspective, and is also the most profitable (almost 50% operating margins). This business is now headed up by Victor Peng, the former CEO of Xilinx.
Investment Thesis
1. AMD’s technology roadmap and execution has given it a competitively differentiated position
While undoubtedly AMD has been able take share in part due to Intel’s complacency and falling behind TSMC in fabrication over the last eight years, full credit needs to be given to several astute technological and strategic bets that AMD has made that set it apart from the competition.
The first is that in 2019 AMD made a strategic decision to rely almost entirely on TSMC for its fabrication. This is significant because TSMC is at the forefront of leading edge chip fabrication, having already commercialised its 5nm process node which powers AMD’s latest EPYC 4 Genoa series of CPUs, and are currently in full preparation for the 3nm process node. Meanwhile Intel has fallen behind now by a full node (7nm is only being deployed in earnest this year with their Saphhire Rapids CPU). AMD has become the second largest customer of TSMC after Apple, and as a result of this symbiotic relationship TSMC is willing to make significant investments in new capabilities like advanced packaging for which it will be able to bank on AMD as an anchor customer. For instance, AMD’s latest and greatest AI accelerator MI300 is not just being fabbed at TMSC but also entirely packaged there as well using their CoWoS platform.
The other cornerstone of AMD’s technological edge is its decision a decade ago to lean heavily into chiplet architecture. AMD’s decision to go down this route was due to them foreseeing the limitations of Moore’s Law (the idea that transistors on a chip would double every two years) as the industry would eventually run up against the laws of physics. The costs of fabricating smaller and smaller process nodes with higher transistor density is rising rapidly.

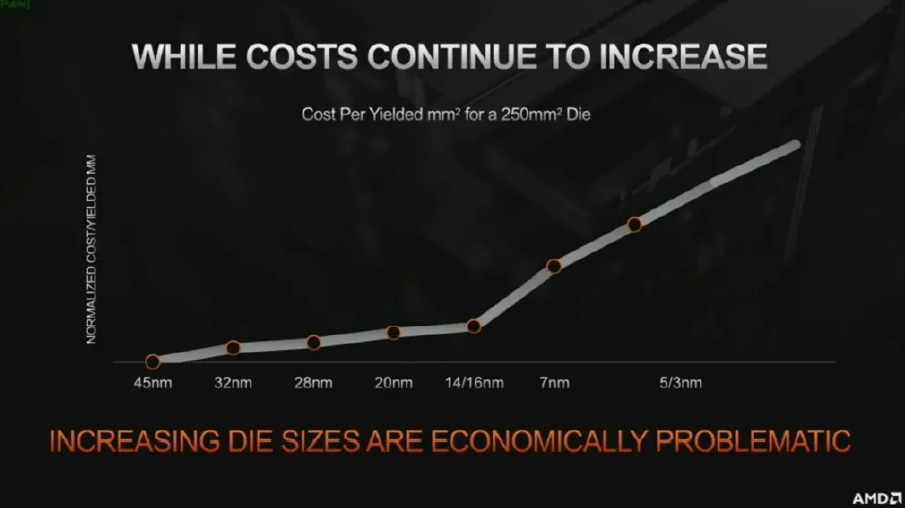
One way to circumvent the slowdown of Moore’s Law is to build larger chips which could package more transistors. This has limitations however due to the lithographic reticle limit (mask sizes), which is a practical ceiling on how large silicon die can be manufactured. Larger chips also have yield concerns as they have higher chance of defects, and one defect on a chip usually means throwing the whole die out, a loss that the chip company needs to absorb. This is why Nvidia’s powerhouse flagship GeForce 4090 GPU cards with their massive 76bn of transistors has such a comically large size and hefty price tag (they are not getting any higher margin on these chips - the price uplift is necessary to absorb the rising costs).
Chiplets is one of the main solution to extend Moore’s Law. At a high level, it refers to the partitioning of a single monolothic die into multiple dies, which are then bonded together to create one chip. Manufacturing of smaller dies results in significantly higher yields due to lower defect rates and thus lower costs, as well as faster development times, all while still generating approximately the same performance as that of a monolithic die. This results in greater flexibility in production and more importantly significant cost efficiency and savings - c. 40% cost saving according to AMD.

The modularity of chiplets gives AMD flexibility to combine different permutations and combinations of silicon - diversity of nodes in every generation of chips. For example, you could have the more expensive leading edge process nodes on the core compute component (7nm for instance), and older cheaper process nodes (eg. 14nm) for non-core components, such as I/O die1. This results in cheaper chips for relatively comparative performance.
Chiplets has been a key reason for AMD gaining share against Intel in CPUs, and could potentially put a challenge to Nvidia in GPUs. As Antonio Linares points out in his excellent deep dive, AMD’s decision to go down the chiplet route is analogous to The Innovator’s Dilemma. For many years industry incumbents like Intel dismissed chiplets as a viable idea due to the uncertainty of whether it would even yield performance and cost improvements due to the complexity of the approach, as well as the significant upfront engineering and R&D costs required. As with most new innovative ideas, it isn’t obvious at the time that they will be successful, as otherwise everyone would be doing them. However, having seen the performance and market share gains that AMD has gained as a result, all of them are now starting to explore chiplets, however AMD’s lead here is many years ahead.
First gen EPYC Naples server chips (launched in 2017) were the first to implement chiplets, and AMD would go on to deploy chiplets across its entire portfolio - consumer CPUs (Ryzen), data center CPUs (EPYC), data center GPUs (MI200, MI300), and most recently in its latest consumer GPUs (RDNA 3). Xilinx has also been using chiplets in its FPGAs, which brings strong alignment with AMD.
Referencing Antonio yet again, the flexible coordination of such a unified technological approach across different teams, products and market segments requires a very strong, cohesive and integrated organisational culture and structure. This culture seems to have been established under CEO Lisa Su and is one of the company’s core strengths.
“In addition to the technical challenges, implementing such a widespread chiplet approach across so many market segments requires an incredible amount of partnership and trust across technology teams, business units, and our external partners,”
“The product roadmaps across markets must be carefully coordinated and mutually scheduled to ensure that the right silicon is available at the right time for the launch of each product. Unexpected challenges and obstacles can arise, and world-class and highly passionate AMD engineering teams across the globe have risen to each occasion. The success of the AMD chiplet approach is as much a feat of engineering as it is a testament to the power of teams with diverse skills and expertise working together toward a shared set of goals and a common vision.”
Chiplets is one approach to mitigate the death of Moore’s Law, but on its own is not enough. The next wave of efficiency is likely to come from other advanced packaging techniques2. Essentially the idea behind packaging innovation is to connect chips or sub-components of chips together as close as possible on the same wafer or on other chips via interconnects, reducing latency and power usage. Here AMD has also been on front foot. In collaboration with TSMC it had been innovating around 3D packaging techniques, which involves stacking dies on top of other active dies3.
The first application of this technology was AMD’s 3D vertical cache in its Ryzen 7 consumer CPUs and 3rd gen EPYC (Milan-X) server CPUs. Here they stack memory on top of the core computing dies on the CPU via hybrid bonding, allowing them to triple the amount of the extremely fast L3 cache memory on the CPU. By caching more of the workload in L3, AMD claimed it could increase the throughput in bandwidth intensive workloads by a significant margin.

As is hopefully becoming clear, AMD has the concepts of modularity and flexibility in chip design deeply embedded in its ethos, and when you pair this with its range of technologies you can create some powerful combinations. For example, AMD has long been a pioneer of what it calls the Accelerated Processing Unit (APU) in its consumer laptops, where it combines a CPU, GPU and memory on a single chip connected together with AMD’s Infinity Fabric. I think of these as similar to integrated graphics but more advanced - APUs dedicate more silicon space to GPUs which enables more higher end graphic rendering tasks (although still nowhere near the performance of dedicated GPUs like GeForce or Radeon).
Most recently however AMD has demonstrated its ability to combine CPUs+GPUs in the data center with its latest generation, monster accelerator, the MI300. It is the world’s first data center CPU and GPU combined on a single chip for AI and HPC purposes. It’s a massive chip which is configurable to have various numbers of CPU or GPU tiles together with high bandwidth memory. According to SemiAnalysis “The MI300 makes Nvidia’s Grace-Hopper look silly from a hardware integration standpoint”4. This may be the chip that finally wins AMD some share in the data center accelerator market vs. Nvidia:
“The big hardware win is allegedly at Microsoft with AMD’s MI300 line of CPU/GPU. Microsoft will obviously still buy Nvidia, but a decent size of MI300 will help start to break the moat. AMD’s strong point here is its hardware engineering. AMD’s next-generation MI300 is a marvel of engineering. AMD’s claims for performance per watt are stellar. While Intel and Nvidia have visions of combining GPUs and CPUs into the same package, AMD will start installing them into next-generation HPCs in H2 of 2023. Furthermore, AMD is doing it all in one package with truly unified HBM memory. We have written exclusively about the packaging of MI300 in the past, but it will be unique, far ahead of what Intel and Nvidia will deliver in the same time frame.”
How Nvidia’s CUDA monopoly in machine learning is breaking, SemiAnalysis (16-Jan-23)

In summary, AMD’s technological prowess and roadmap has positioned it well from a competitive standpoint, and short of an uncharacteristic execution failure, I see this differentiation continuing to persist over the medium to long-term.
2. Consistent share gains in data center CPUs + possible share gains in GPUs
By Intel’s own admission, they will likely keep losing market share to AMD in the data center through to 2025, by which point they expect to catch up to TSMC in leading edge node fabrication. While it’s possible, this will require them to do 5 nodes in 4 years, which most industry analysts think will be a stretch due to the complexity and massive capital requirements of producing 5nm, and eventually 3nm and 2nm process nodes. So we can expect AMD to keep gaining share for years by leveraging TSMC’s fabrication lead. Looking at public cloud CPU deployments share data from Jefferies tells a pretty clear picture.5

Intel has inevitably been forced to follow suit on chiplets with its Sapphire Rapids CPU launched late last year (after many delays) and deployed in full this year, but as mentioned it’s based on the 7nm node and a full generation behind AMD’s Zen4 Genoa series which is using TSMC’s 5nm process node. Together with various design features in Genoa which give it a significant edge over Intel, AMD’s market share gains looks set to continue. I will come back to Intel’s roadmap in a bit in the Risks discussion.
Looking at the ramp by chips below, what is also interesting is that every new generation since EPYC 1 Naples has seen a faster uptake than the previous. According to management (and seen in the data below), the last gen Zen3 (launched in 2021) is growing strongly still, and this momentum bodes well for its newest generation Zen4 Genoa which promises 2x the performance of Milan. According to SemiAnalysis, ”The reality is that Genoa and Bergamo [also part of the Zen4 line up] will drive the most extensive datacenter infrastructure replacement cycle since at least Broadwell and Skylake.”

Up until recently it was a similar story in the consumer market. As can be seen below, AMD has been on an upward climb in the notebook (laptop) and desktop markets. This has been stemmed recently by Intel’s aggressive channel-stuffing and pricing discounts, which AMD hasn’t been willing to engage in, resulting in the sharp decline we started seeing at the back end of last year. Also, while the below chart shows unit share, revenue share would be higher for AMD given their focus is on the high-end of the laptop and desktop market. Overall my sense is that in the consumer market having the latest bleeding edge processors is less of a priority, and based on various hardware reviews Intel and AMD seem to be much more evenly matched in terms of value proposition. So while AMD is well positioned, it is a bit more difficult to underwrite consistent market share gains for them in this segment.

As for the GPU/accelerator market, as discussed in Nvidia part 3, so far AMD’s traction has been limited. Despite having some high profile deployments of its MI Instinct accelerators in the US Department of Energy supercomputer El Capitan, commercial deployments to date have been limited.
What is clear is though is that AMD is closing the gap to Nvidia, at least in terms of hardware performance. In the consumer market, its latest gen Radeon 7900 series of GPUs have been getting good reviews and are a worthy competitor in terms of performance per dollar to GeForce 4080 in the mid-end of the market (GeForce 4090 still stands alone at the very top end). In the data center, Nvidia and its CUDA-powered GPUs have a firm grip, but what will be working in AMD’s favour is that customers would love to have a credible alternative to Nvidia. Meta, for example, has developed what it calls its AITemplate, an engine which allows for more flexible switching between AMD and Nvidia GPUs for inferencing. And as mentioned earlier the MI300 is getting early hyperscale wins with Microsoft. It wouldn’t be surprising to see AMD start to take a bit of share from Nvidia in both the consumer and data center market.
3. Wide portfolio of chips - CPUs, GPUs, FPGAs, DPUs and all sorts of custom silicon — positions AMD well for a future of heterogenous and customisable computing
In my Nvidia deep dive (part 3) I highlighted that a key risk for Nvidia is that it has obviously put all its eggs in the GPU basket, and would be at risk of a future where heterogenous compute is more prevalent. While GPUs and Nvidia are currently the default standard for training AI models due to their superb ability to crunch multivariate matrix arithmetic in parallel, they are a general purpose computation chip and are not the most efficient for all tasks. For instance AI inferencing (taking the trained models and using them make predictions in real life settings) requires optimising more for speed, cost and energy efficiency rather than brute force computing power. AI inferencing is expected to be 2-3x larger than training, and CPUs are still heavily used in this area.
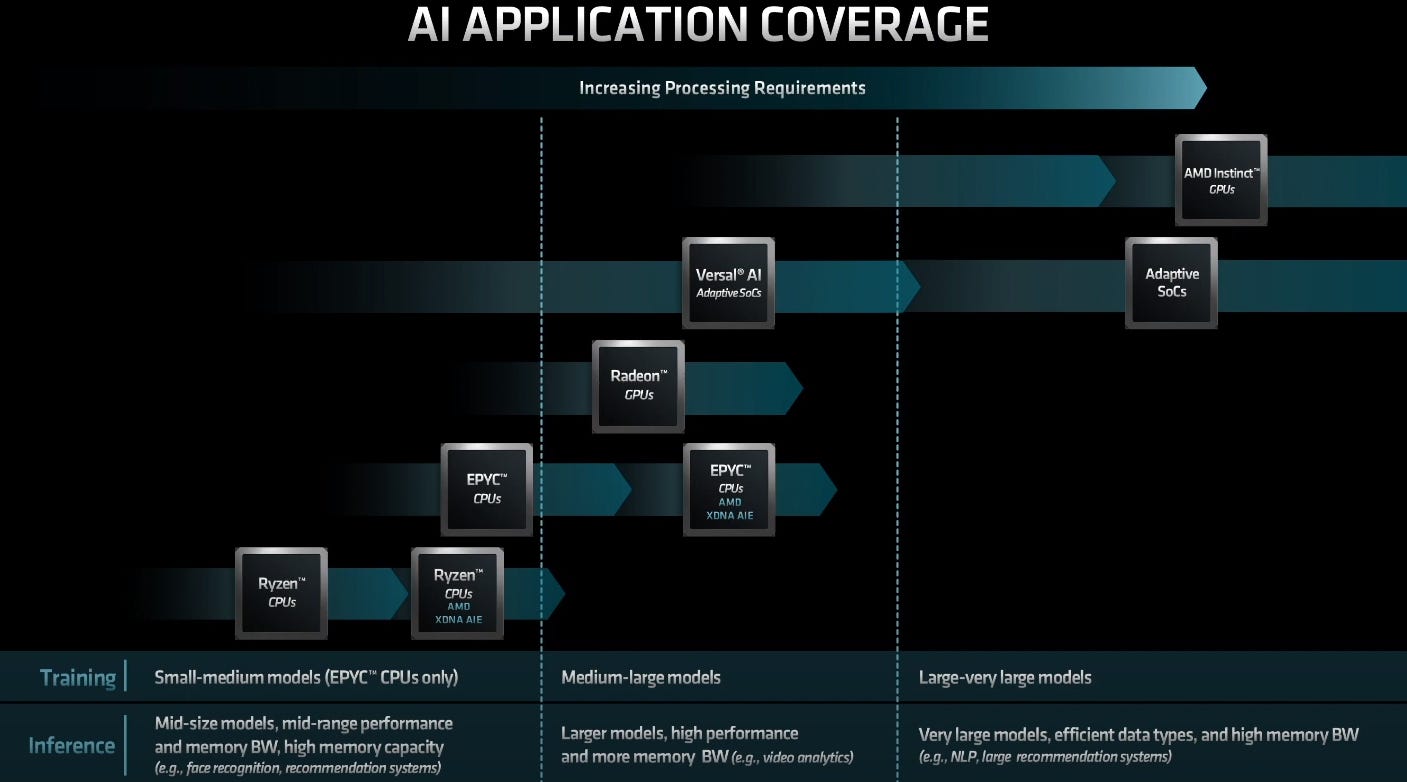
The below chart provides a good summary how AMD’s offering of chips caters to the full range of AI training and inferencing applications of various model sizes; Ryzen consumer CPUs for the lightest workloads, EPYC server CPUs and Radeon GPUs for medium-large workloads, MI Instinct accelerators for the heaviest-duty workloads like large language models.
At this point it’s probably worth mentioning ChatGPT which has completely captured the cultural zeitgest. Undoubtedly Nvidia has been the key beneficiary of this, as these large language models are trained almost exclusively on tens of thousands of its GPUs, and are being inferenced on them to a large extent as well. Morgan Stanley’s research suggests however that the desire to keep pushing the costs per query down should open up the opportunity for cheaper alternatives than Nvidia’s flagship GPUs (which are largely designed for training and may be somewhat of an overkill for inferencing):
“[costs] should come down materially as it becomes a major focus - and that will likely create a very competitive market. NVIDIA inference products are compelling, but the significant focus on costs is going to open up opportunities for others. NVIDIA has a strong opportunity, but so does AMD, Intel (with Habana assets), several startups, and custom silicon.
“Context on the Nvidia Chat GPT opportunity” Morgan Stanley research (10-Feb-23)
In a lot of cases, purpose-built ASICs6 for singular use can do an even better job than CPUs and GPUs at specific tasks. FPGAs7 are a type of ASIC that can be reprogrammed after manufacture, making them quite versatile little chips. Xilinx is the market leader in FPGAs and their chips are used extensively in various industrial edge cases such as telecommunication, aerospace, industrial and healthcare. In these industries where edge devices need to be able to make fast computations it is much more practical and cost-effective to use these smaller FPGA chips than high-powered GPUs or even CPUs. For example, Xilinx FPGA solutions are used in healthcare robotics, industrial machine vision, and intelligent vehicles, amongst many others. The demand for all of these edge use cases will only increase with 5G, and Xilinx is well positioned to ride that wave. AMD estimates that the embedded segment has a TAM of $33bn. In short, Xilinx and its FPGAs have unlocked a potentially very large market opportunity for AMD.
More so, just like we’ve seen with the MI300, AMD is utilising its prowess in chiplets, stacked chip packaging and modular designs to combine its CPUs with Xilinx's FPGA-powered AI inference engine - what it calls its XDNA architecture. It is beginning to deploy this in its Zen4 server processors as well as some of its consumer CPUs. This will give AMD a further advantage in a variety of AI inferencing workloads - again think about the large inferencing opportunity just with large language models like ChatGPT alone.
What is clear is AMD has the flexibility to fuse together any type of chips, together with its Infinity Fabric, a system of high-speed interconnects similar to Nvidia’s NVLink fabric. It has a plethora of options for its own proprietary future products. AMD also does custom designs for customers looking to develop their own specialised in-house chips but lacking the capability to do so. The trend for custom silicon is one that has been well established in the industry (peers like Broadcom and Marvell have a large custom silicon business), and while this does pose a risk of cannibilising its core, higher margin chip business, AMD realises that fighting this trend is futile and uses these services as a way to strengthen its relationships with customers who may buy its catalogue chips in the future.
“Customers have come and asked us, “hey, can you help us differentiate? We don't want to build all the general-purpose stuff that you guys are doing because you have the scale in the general-purpose stuff , but we want to be able to add our secret sauce.”
We already have the leading industry platform for chiplets, but what we're doing is we're going to make it much easier to add third-party IP as well as customer IP to that chiplet platform.”
Lisa Su (CEO)
Finally, AMD has a strong presence in networking solutions through Xilinx (who offers Alveo data center accelerator cards, which are highly used in the financial services sector, namely high-frequency trading firms) and its most recent and smaller acquisition of Pensando, who specialises in advanced DPUs (data processing units). I discussed the value proposition of DPUs in Nvidia Part 3, but in short DPU penetration of servers will only increase over time as infrastructure and data management needs grow. We can see the demand for all of these networking solutions coming through strongly last quarter:
“We had record sales of our Xilinx Data Center and networking products in the quarter, led by strong demand from financial services companies for our newly launched Alveo X3 series boards, optimized for low latency trading. Sales of our Pensando DPUs also ramped significantly from the prior quarter, driven by supply chain improvements and continued demand. We are very pleased with the customer reception of the Pensando technology with good long-term growth opportunities as DPUs become a standard component in the next generation of cloud and enterprise data centers.”
Lisa Su (CEO), Q4’22 earnings call
Nvidia is obviously aware of these heteregenous compute trends and has been customising its GPUs and developing software to make itself relevant in AI inferencing, edge computing, robotics, automotive etc. It is also launching its own Grace CPU, and given itself a solid presence in DPUs and networking via the acquisition of Mellanox. As a result it may win decent market share beyond its core market of training AI models. Nonetheless, according to one expert interview on Third Bridge “whoever could offer the best compute portfolio across GPUs/CPUs/ASICs as a vertically integrated company going forward will have a longer-term advantage”. AMD fits this profile extremely well.
Risks
Competition
AMD faces competition from a multitude of players, which means their position is constantly being challenged and they need to keep innovating to stay ahead.
Intel: While Intel continues to be plagued by execution issues, they should never be ruled out, especially under the helm of Pat Gelsinger who is generally well-regarded in the space. The below table lays out Intel’s fabrication and CPU roadmap against TSMC’s fabrication and AMD’s CPU roadmap.
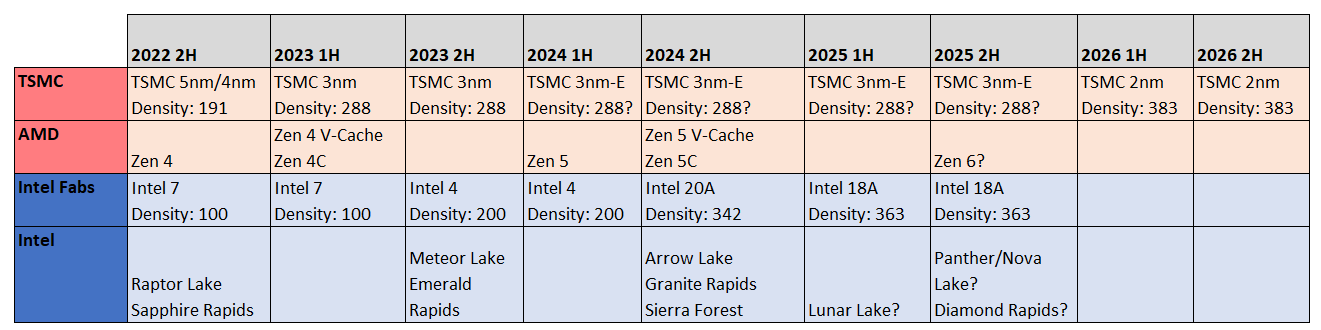
Intel is looking to not only catch up to TSMC, but surpass them by 2025, by which point they claim they’ll be able to launch the 2nm process node (which they are calling Intel 18A), while TSMC is only planning 2nm for 2026. If Intel can truly achieve this, then AMD’s lead may be neutralised. We’ve also seen how Intel is not afraid to be aggressive on pricing to take back share at the cost of their own margin, as they’ve done in the consumer market recently.
Looking at Intel’s CPU roadmap, it is similarly aggressive, with plans to launch a whole series of consumer and data center CPUs in the next two years to try win back share. Also while AMD is very well positioned in the public cloud, in the enterprise segment Intel may be better placed due to specific design choices in its CPUs that make it more suitable for that market8.
Further, while AMD is at the forefront of chiplet design, Intel is similarly deploying chiplets (which it calls Tiles) in its CPUs, starting with the recently launched Sapphire Rapids. It is also deploying advanced 2.5D and 3D packaging through its EMIB (embedded multi-die interconnect bridge) and Foveros technologies respectively. Finally, it’s also worth adding that Intel’s Foundry Services together with its EMIB packaging technology have found themselves some strong validation as they have been chosen as the packaging partner for AWS’s Graviton CPU chip - a nice segue to the next point.
Tech giants and their in-house chip: All of the hyperscalers from Amazon to Microsoft to the Chinese players are ramping up internal chip design teams and developing their own chips, with the rationale being that these chips are fit-for-purpose and reduce their total cost of ownership per unite of compute. Even if AMD, Intel and Nvidia’s designs are better, they will never cater perfectly to what these large customers need. As the hyperscalers represent the majority of data center spend (60% of CPU TAM according to AMD), there is a risk that AMD and its peers eventually get commoditised.
AWS is the biggest threat here as 1) it is the largest public cloud provider, and 2) it is by far the most advanced in terms of CPUs with its Graviton chip. Graviton is an extremely high-performing chip, and as per the market share data from Jefferies below, is being rapidly pushed in AWS cloud deployments (unsurprisingly) - it now accounts for a larger share of AWS cloud deployments than AMD.

Clearly AWS is still buying a lot of AMD chips though and will likely continue doing so for some time, a view corroborated by various experts:
“I don't see them [AWS] completely switching out their entire system just to go with their own chips. But I guess you could say they'll take back a few percentages, but it's not life-threatening or it's not a huge deal-breaker for AMD or Intel”
Former Senior Product Engineer at AMD (Tegus expert transcript)
Nonethless it’s another reason for why it is crucial for AMD and its peers to keep innovating and providing strong performance-per-dollar spend on its chips to stay relevant.
Software
As covered in my Nvidia articles (particularly part 1 and part 3), Nvidia has a clear dominance in GPUs in both consumer and data center. Even though AMD is closing the hardware performance gap, software is still currently a clear differentiator for Nvidia, while being a constant problem for AMD. This is something it will need to resolve if it wants to give itself a serious chance of capturing GPU market share.
“While Intel and Nvidia have a long history of software development in support of their chips, the same can’t be said of AMD. “We like the looks of the MI300 and the roadmap, but the software ecosystem is still a problem,” said Tease (Lenovo’s vice president of HPC and AI, tell). “It’s still not turnkey and easy for run-rate customers.”
AMD’s attempt at a CUDA type software framework, called Radeon Open Compute Platform (ROCm), has seen limited traction (evidenced by the fact that unlike Nvidia, you don’t ever see AMD talk about its developer ecosystem on earnings calls). AMD’s software approach has also lacked coherence as for a long time it’s been pushing the OpenCL standard as well as ROCm. Part of the problem is that historically AMD has struggled to attract strong software talent. This has been somewhat ameliorated with the Xilinx acquisition, which brought in a significant cohort of talented software engineers and Xilinx’s well-developed software framework called Vitis. Now former Xilinx CEO Victor Peng has been tasked to lead AMD’s AI and software efforts, which will involve integrating its existing ROCm platform with Xilinx’s. The idea is that the ROCm stack will do most of the heavy lifting on the training front, but a unified front-end of ROCm+Vitis - together called AMD Unified AI Stack 2.0 - will be developed for inferencing, which should allow the use of any chip for any use case. They are also talking about developing a range of software libraries and SDKs, similar to what Nvidia has been doing for ages. That’s the vision, and time will tell whether this will be successful, but Lisa Su is clearly aware of their deficiency here and is highly focused on resolving it.

“[Developing software] takes much longer than most people would realize. And I think they [AMD] had several experiences, which were understaffed, underfinanced. And I think they've been doing something more serious for about at least three years now. And they're coming with something that's a little bit promising that I see from time to time. So they are not there yet, but they're getting much more close to having the stack, which makes sense.”
Former Head of AI Developer Relations at Nvidia (Tegus expert transcript)
Forecasts
In their 2022 Financial Analyst Day AMD put out a long-term financial model of what they expect to achieve over the next five years or so.

I think these guidelines above are broadly realistic given where the company is today. In my modelling I have given them credit for the Operating Profit and FCF margin targets, although I was more conservative on revenue growth to account for macro weakness and general conservativeness. Below is a summary of my base case forecasts

For the sake of brevity I will not write out all the assumptions here in detail, but at a high level these forecasts assume the following:
Data center: 21% revenue CAGR vs. overall server data center spend of around 15% (see Nvidia Part 4). I assume they continue to take share in Data Center, growing faster than Intel in CPUs, with an increasing contribution from its GPU and advanced networking products (from a low base). Data center revenues in this case get to around $19bn in FY28, and whilst AMD’s doesn’t disclose the exact split by products, it would be reasonable to assume that majority of this is CPUs. If we assume for example that 80% of this is CPUs ($15bn), and compare it to AMD’s estimated TAM for server CPUs over the next 5 years of $42bn (from the 2022 Financial Analyst Day), this would imply about a 35% market share, which I think is a reasonable increase from the c. 20% they have today.
Embedded: 6% revenue CAGR based on some market forecasts that I found for global embedded systems growth. This is a relatively mature market so high growth rates shouldn’t be assumed here
Client and Gaming: Continued macro weakness and post-COVID slowdown in 2023 impacting the consumer Client and Gaming businesses, recovery in 2024, and a moderate 5-8% revenue growth thereafter. My forecasts here I think are a reasonably conservative, for instance I assume that Client doesn’t reach its peak 2021 revenues again until 2027
Profit and FCF: Operating profit (as defined by the company in this case, ie non-GAAP) reaches and slightly exceeds 30%, and FCF margin reaches and slightly exceeds 25%, as per the company’s long-term guide
For further details feel free to reach out. The net result is revenue growing from $23.6bn in FY22 to c.$41bn in FY28, a 10% CAGR, which is far lower than the company’s long-term guide of 20% growth. Operating profits and FCF reach c.$13bn and c.$11bn respectively by FY28.
Valuation
I have valued AMD on a free cash flow multiple basis, although the street mostly use P/Es (based on non-GAAP NPAT). Given the relatively high cashflow conversion between non-GAAP NPAT and FCF for AMD, it would be a reasonable approach to apply a FCF multiple with reference to the company’s traded P/E range. At the current price of $97 it is trading at 32x forward P/E. This is a premium to where it’s traded over the last year (~22x average), but still lower than it’s 3 and 5 year averages (37-38x)

For the purpose of calculating returns, I’ve assumed an FY27 exit off the FY28 cash flows (5 year hold), at which point I think a contraction to a 20x multiple is reasonable. This accounts for the slower growth in the outer years, but still values AMD at premium to Intel (13-15x longer term average) as I believe it will retain its stronger position. Given how sensitive the exit multiple is to returns I have sensitised it below with a range of 15-30x range, which I think fairly accounts for upside and downside cases.
Returns
The below table summarises the cashflows and return calculations. In regards to the treatment of share-based comp (SBC) which in AMD’s case is about 4% of revenue, I have modelled in the associated dilution from SBC through the forecast period, although this is more than offset by the buybacks I've assumed which is why the shares outstanding decreases over time. I then fully included the SBC expense in the final year cashflow that’s used to calculate the exit price, as otherwise you’d be ignoring the fact that SBC would persist into perpetuity

Assuming a 20x FCF multiple, I derive a share price in 5 years of $150, which is a 10% IRR from today’s share price of $97. I think this is a reasonable return under what I believe is a conservative set of assumptions.
Given the sensitivity of the returns to the exit multiple, below is a sensitivity around the range of 15-30x, with the bottom of 15x reflecting Intel’s multiple in a downside situation, and the upper end of 30x reflecting a multiple closer to AMD’s historic trading range. This results in an IRR range of about 3%-20% over the next five years.

Thank you for reading. Hit me up with any feedback/comments/holes in my thesis etc, either below or on Twitter @punchycapital. And of course a retweet or a share is always appreciated and keeps me going.
Some good sources for further research on AMD and the sector:
Antonio Linares deep dive “AMD: Positioned to Become an AI giant” (strong recommend)
Asianometry YouTube Channel (strong recommend)
The Next Platform
With ROCm software and instinct MI200 GPUs, AMD has ecosystem critical mass
Data center and Xilinx power through in Q4 and beyond for AMD
Intel’s data center business goes from bad to worse, with worst still to come
SemiAnalysis (some behind paywall)
AMD Genoa detailed – architecture makes Xeon look like a dinosaur
2023 datacenter outlook – AMD and Intel revenue, ASP, and units – Genoa ramp details
Company presentations + interviews with CEO Lisa Su
Other
Input / output die (or I/O die) is the component of the CPU that interfaces with system memory and the motherboard
Advanced packaging refers to the integration of several chips on a single die to achieve higher component density and efficiency
Alongside the more advanced 3D packaging, 2.5D packaging is extensively used by chip designers. This refers to placing chip components side by side on a connective substrate, a method that’s been used by many chip designers including Nvidia in its A100 GPUs and AMD in all of its Zen3 and Zen 4 CPUs. 3D takes it up a notch by placing chip components directly on top of other chip components. This is a very complex and more costly process in return for efficiency gains of less die space and lower latency.
What Nvidia refers to as the Grace-Hopper superchip isn’t actually a CPU and GPU on one chip like AMD’s MI300. The Grace-Hopper is a side by side package connected with NVLinks. The major disadvantage of this is that it still must transfer data out of the package to go between the CPU and GPU. While this uses NVLink, a relatively high bandwidth, low latency link, it does not compare to on-package transfers in latency and bandwidth.
These charts only show share of public cloud deployments, which according to AMD represents about 60% of the data center TAM. The other key segment is Enterprise, and here Intel appears to be more dominant.
ASIC stands for application-specific integrated circuit, which is a highly customized chip for a particular use, rather than general-purpose use like a GPU
FPGA stands for field programmable gate array,
See The Next Platform article “More CPU cores isn’t always better especially in HPC” in Sources list above for more details on why Intel’s Sapphire Rapids CPU may be better suited to enterprise customers than the hyperscalers
This is fantastic - I've wanted more insight into the world of chips ever since your Nvidia post, and you really delivered here.
Wow, your articles are just another thing. Spectacular write up